Those death-knell types seemingly aren't aware of what day to day operations looks like and how AI makes a great tool, but doesn't necessarily deal with the very human factors of whims, uncertainty, reactive business mentalities and the phenomenon that is best summarised by this webcomic: https://theoatmeal.com/comics/design_hell
In my field they like to call this "hurry up and wait", a nonsensical but fitting description that summarises everything from changing scope to the unjust imbalance of time between the principal and the agent.
(There is a comment further down which suggests that we could just train AI to deal with this variability, I hope that's humour... sweet summer child thinks you can train AI to predict the future.)
Companies are already bloated, imagine when they realize one overworked highly paid senior can replace 10 juniors.
A lot of projects today are not even greenlit because they would be too expensive to make. For instance, there are a lot processes in almost every country that require you to file paper forms, even though we have had web forms and databases for 25 years. This goes even for rich countries. If one programmer is able to do the job of 5 others, we will probably have 5 times as many systems to tend to now that businesses and institutions can afford them.
I'm still a bit bummed about it, because just writing and structuring code is something that often brings me joy (and maybe your wife feels similarly about the actual translation work...), but at the end of the day, I realized well before all this AI craze that it really isn't the most valuable thing I do in my job.
And instead of the 97% unemployment our intuition tell us would happen, we're instead 30x as productive.
The same will happen when/if AI makes writing software far more effective.
Economic productivity simply means output per worker. So, we could make 97% of the US population permanently unemployed tomorrow, and as long as the AI replacement labor yielded equal or greater proceeds to the remaining 3%, we’d see a colossal increase in “productivity.”
That would be in the interest of the 3% to do (or attempt), which is what makes the scenario so scary.
The only reason it's not the case in this example is because computers at the time were a tiny early adopter niche, which massively multiplied and expanded to other areas. Like, only 1 in 10,000 businesses would have one in 1950, and only big firms would. Heck, then 1 in 100 million people even had a computer.
Today they've already done that expansion into all businesses and all areas of corporate, commerce, and leisure activities. Now almost everybody has one (or a comparable device in their pocket).
Already cloud based systems have made it so that a fraction of programmers and admins are needed. In some cases eliminating the need for one altogether.
There are tons of other fields, however, more mature, where increased productivity very much equaled job loss...
Notice that during that time there weren't all of a sudden less programmers, or managers or sysadmins, if anything there's more. If anything everyone is even more stressed with more to do because of the context switching and 24/7. That's why this will do, I'd bet money on it.
Increased productivity doesn't necessarily lead to overall job loss, but it will eventually in the area where the productivity is realized. Agricultural employment is a very clear example.
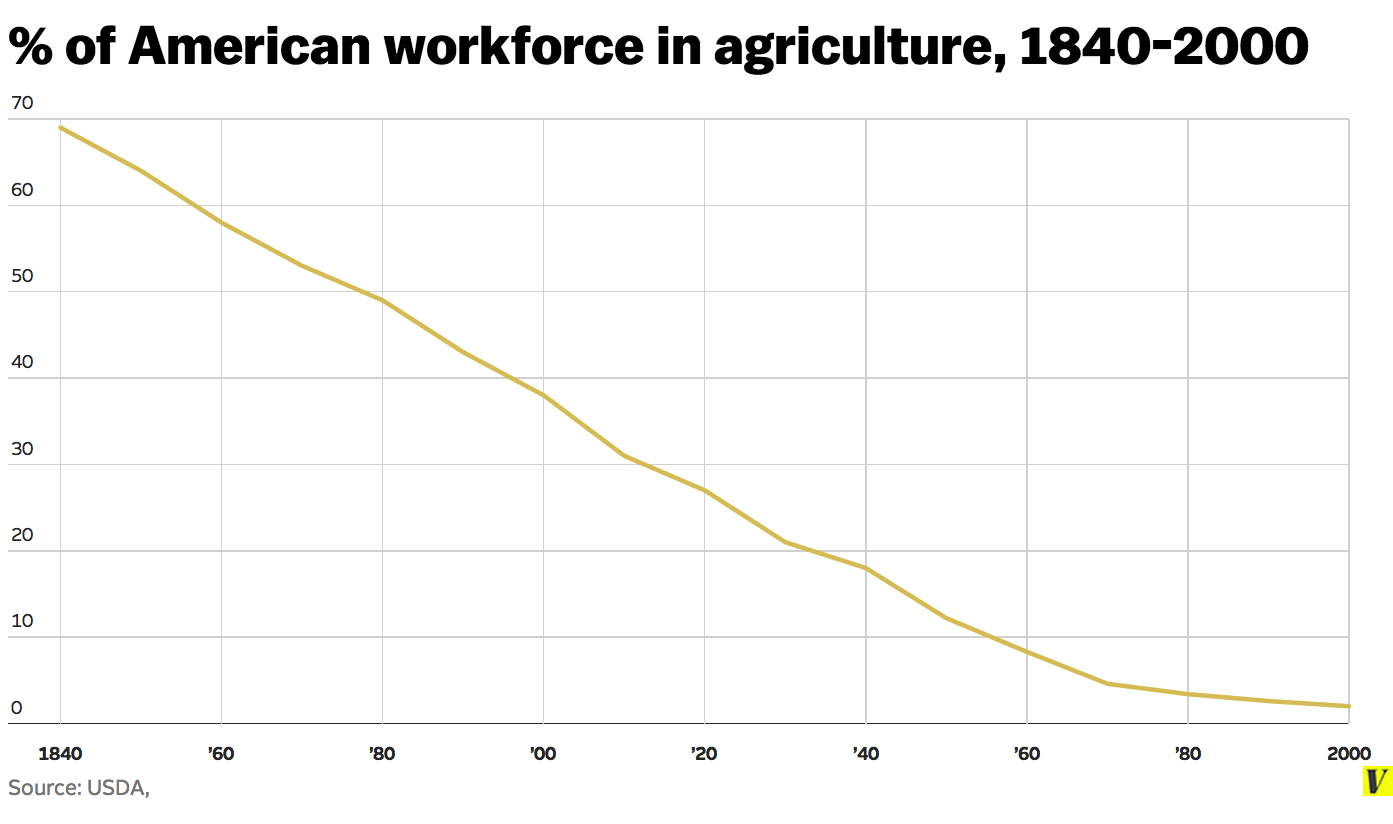{kind=link}
Yeah. The problem is that there’s only one of me. All the rest of you are filling in for the other guy.
Yep. This is where I'm at in terms of personal armchair predictions of the future.
I expect the labor market will be tough for more junior software engineers in the coming years. This might indeed cause backpressure in the supply of new grads/new labor force entrants in this family of fields ("software development").
However, the "highly paid senior" is only around for so long before achieving financial independence and just not working anymore. Then what? The company didn't hire juniors because the "highly paid senior" did all the work. Whoops. Now the company lacks the pipeline of people to replace that senior.
It'll sort itself out in time, but the next decade will be interesting I think. Some companies will realize that they must make investments into the future of the labor force and will do better in the longer term. Other companies might indeed "fire the juniors" for some short term gains and find themselves lacking replacement staff later.
Now some might say that the code will be terrible quality and buggy and full of holes and the users will hate it, it is never economically viable to build enormous systems on a house of cards like that. To which I respond, you just described every piece of enterprise software I've ever used ever.
I've seen entire businesses collapse because of this mentality.
Getting juniors un-stuck on "simple" problems, maybe. Stack Overflow already does this. Image doesn't build? Search for the error message online. Don't know how to build the old software that only works in Ubuntu 14.10? Sure, you'll find that.
Suggestions on how to refactor, proper design of interfaces, what skill to acquire next? Maybe, but that will be a bigger surprise.
Every org has varying level of engineers. This technology will make cheap grind, well cheap. We see the progression. With the speed of changes it seems we should all be worried. (as why does it matter despite being last we fell a year after)
That is already possible without AI and has been the case for a long time... the issue is nobody will stay to be that highly paid senior running entire projects because at that point you can just run your own shop and pocket the full profits.
I'm not disagreeing with you. Im thinking of going solo myself.
Not to say that this is a bad thing, but the difference between a junior and senior is often much more than the difference in their salary.
Except, there was no AI, but an alternative called an offshored development center. You would send your spec and design document and get, via email or FTP if they were really cutting-edge a number of files that would sometime compile and even, according to the legends, actually work. The way this tech worked is that you generally had to wait overnight for your spec to "mature" into code.
Some places figured out they could hire local engineers for about 5-10x what they paid for this "offshored development center" tech and get better results.
This already happens, the market is just not very efficient about it, e.g. a highly paid senior dev is not working at a company that only needs 2-3 developers, they're working at Google with 100's of devs.
Developer time reduced by 5X CPU time increased by 500x
When CPU cycles are cheap it's a logical tradeoff but it still grates against my sensibilities.
It makes more sense to tune libraries excessively, we could say it is less of a trade off, more of an allocation of the finite low-level tuning developer resources to high-impact libraries.
Anyway it turns out that the only way to get most people to link to a good BLAS is to use Numpy and distribute it through some giant Anaconda Rube Goldberg machine, so, I dunno, people are weird.
It's some kind of philosophical question.
Maintaining an assembly version of a modern software stack is not 5x more costly, it's simply not possible.
If an inefficiency saves a developer 10 days of work, but results in an operation taking 100 milliseconds longer, and you have 50M customers who do that operation just one time, then you've wasted ~58 customer-days.
I mean, I already do? And for totally mundane and benign reasons. This has been my experience in this industry for the last 8 years or so, though my first 9 years I felt like the pace was maintainable.
Do more with less. It's so common to come across situations where so and so left, their position won't be backfilled, the targets don't adjust to compensate for the productivity hit, and we can put up or shut up.
Additionally there’s the math behind it. If Company A fires 50% of their staff because AI lets the remaining 50% work at twice the productivity then how will they compete with Company B that keeps their staff and now gets 200% efficiency?
The math is in favor of getting more, not fewer, developers.
Also, if your one programmer dies you now have no programmers and loss of all institutional knowledge, whereas the other company can lose several programmers and still be OK. There is value in having redundant programmers.
If they indeed wait for input from other departments/companies 99% of the time (so they just need to actually program 5 minutes in their 8-hour workday), then they can be already thrown out of a job and have the company do with 1/10 the programmers, no AI required...
AI wasnt needed to cut down on bloat - some combination of a few companies reaping the majority of the profit and reduced dysfunction is enough.
If one can go the job of 5 - they revenue per employee will increase.
They will hire even more employees.
Computer Science is not really very much about computers. And it’s not about computers in the same sense that physics isn’t really about particle accelerators, and biology is not really about microscopes and petri dishes. It is about formalizing intuitions about process: how to do things [0].
[0]: https://www.driverlesscrocodile.com/technology/the-wizard-1-....
- Edsger Dijkstra
(And we all atarted writing more quantum algorithms.)
He and Sussman are great at distilling and explaining abstract concepts in a clear and precise way.
Second, relevance and applicability is depending on context. On the context of this discussion, about practical programming in the trenches, what Dijkstra said is irrelevant.
For starters, he was talking about computer science.
Programmers in the trenches (what the thread is discussing) don't do computer science. They merely apply stuff developed by computer scientists (but also by non-scientific practioners in the field), in informal (and often haphazard) manner, to solve business problems (often the same problems again and again, which is something totally beneath a scientist).
So, yes, something Dijkstra had said can still be wrong, regardless of his achievements. And it can also far more easily be irrelevant, as this just needs his saying to be unrelated to the discussion.
Additionally, even if I concede it is an argument solely on authority, just because an argument contains a fallacious point doesn't make it untrue, otherwise that would be the fallacy fallacy.
Notice how you also conveniently sidestepped my arguments about why it's also untrue (on top of containing a falacious point).
"Computer Science is no more about computers than astronomy is about telescopes” - Edsger Dijkstra
- Max Planck
Are you saying Max Planck is wrong here? There is plenty of evidence that he was right, that statements made by famous scientists holds fields back because they were reductive or hurting different perspectives. Putting their words at an altar is holding us back.
More like "it doesn't apply" than "it's inherently invaluable"
Also your comment is technically an appeal to authority
Otherwise if there's a lot of back and forth required or generating a design, forget it. Companies giant and small have tried it and eventually realized "F it" and gone back to in-house teams.
How did that turn out? A whole profession was created.
The thing that comes closest to "no developer needed" is Excel. But you really need someone who knows programming if you want a reliable, robust product, even in Excel.
But for quite a few folks, the coding is the easy part. When building larger systems you're not even that often implementing things from scratch. The decision making, dealing with existing tech debt, tooling, etc. is the hard part. Ambiguity is the hard part and it's always been that way.
Don't get me wrong GPT-* is impressive. Heck, I pay for a subscription. But it won't really make a lot of folks at my company notably more productive.
> The cope of
Whenever I see someone use 'cope' that way, I immediately think they're making a bad faith argument. Is that intentional?
The next step after that is for people to figure out how to justify their continued relevance. I think that’s a pretty natural reaction.
Meanwhile I've got a backlog of about 100 personal projects I've never gotten around to making (especially creating digital versions of my board game designs, of which I have about 70 at this point) that I just haven't had the energy to work on myself, that I'd love to be able to just upload the rules document for it and get some sort of working game spit out the other end, or at least a good chunk of it, and I can take it from there.
And then I can test a new rule by just rewriting the rules document, as opposed to having to manually code every rule change into the game.
I don't think I'd run out of things for it to make if it was as good at complex software generation as A.I. is right now with art generation.
It's good for concept browsing, but not much more for me at the moment.
I'm assuming the process has gotten better since, but I don't know. I'm mostly just using free vector art and simple colors/shapes or whatever simple things I can make in Blender for my art still, in part because there's such a backlash against using any A.I. art right now.
Most of it is judging by what people have been saying in groups online. Some people have found it very useful and use it extensively, like for their board game art.
It doesn't even have to get 100% of the way there (for coding games based on rulesets). Even 75% would probably save me a lot of time and allow me to find the energy to close the gap as opposed to not even starting since I have so many other projects going on.
Also if software development does survive, it's going to look very attractive to all the other unemployed people.
but there is a funny mechanic at play certainly: once some dev work gets cheap as a commodity, demand surges suddenly since at a low enough price point and availability everyone wants to have some need solved that made no financial sense before.
First, if you did have GPT-X (say GPT-10) in your company, there wouldn't be much back-and-forth communication either. Those parts would still be handled with GPT-X talking to another GPT-X in the other company. Even the requirements might be given by a GPT-X.
Second, even if that's not the case, the part of doing the communication can be handled by non-programmers. Then they can feed the result of the communication to GPT-X and had it churn out some program. Perhaps would keep a couple of developers to verify the programs (sort of like GPT-X operators and QA testers) and get rid of the rest.
As for the rest of the current team of developers? GPT-X and the people running the company could not care less about them!
What happens if one (or more) of the GPT-Xs starts having hallucinations while they're busy working on this project?
> Second, even if that's not the case, the part of doing the communication can be handled by non-programmers.
I was in a meeting with a sales manager and tech team a few days ago. Sales manager had been talking to a potential customer about a product that neither he nor the customer properly understood. They both thought it would be an excellent fit for a particular (new) purpose, one for which it was not designed.
As it turned out, everyone on the tech team knew that both sales manager and customer were utterly and catastophically wrong, but it took the best part of an hour to finally convince him of this.
It's quite hard to have useful conversations about stuff if you don't actually understand it.
Also, having conversations about things you don't understand with a machine, where you don't have to keep up social decorum and can ask the dumbest questions should help a lot with improving the decision making of non-technical personel
In the same way that wrong results in a search engine will not be solved or mitigated in its entirety, yes. These new generative AIs are big search engines that bring results from several content points and combine them into a single, plausible stream of words.
This sales manager didn't know that neither he - nor his customer - properly understand the product until he was specifically called out on it (by me, as it happens. At least the boss laughed). Are we expecting GPT-X to sit in on Teams meetings and ask questions like that, too? Sales manager literally did not know he needed to start asking questions about the product. Tech team were calling BS on it as soon as he reported his conversation with customer.
"It ain’t what you don’t know that gets you into trouble. It’s what you know for sure that just ain’t so.", which may (or may not) have been said by Mark Twain.
https://support.microsoft.com/en-au/office/suggestions-from-...
It can’t - only programmers will know which follow up questions to ask. GPT will be able to ask those questions before non-programmers will be able to.
Half the work is nitpicking on date formats or where some id comes from or if a certain field is optional, etc.
Additionally, this is "stateless" to an extent. There's no architectural plan for how it should work when you have an LLM do it. "We're using X now but there are plans to switch to Y in some number of months." This could lead to making an abstraction layer for X and Y so that when the switchover happens there is less work to be done - but that requires forward looking design.
If "they" only describe the happy path, there is no one to ask about all the unhappy paths, edge cases and corner cases where the naive implementation of the problem description will fail.
Hypothetically, yea, "they" could be trained to think through every possible way the generated code could go wrong and describe how the code should work in that situation in a way that isn't contradictory... but that remains an unsolved problem that has nagged developers for decades. Switching to an LLM doesn't resolve that problem.
I've been working on a database migration recently, and I look forward to the rare moments when I get to write queries and analyze actual data. The vast majority of my billable hours are spent trying to tease out the client's needs by going over the same ground multiple times, because their answers keep changing and are often unclear.
It takes a lot of processing to figure out an implementation for someone who will straight up describe their requirements incorrectly. Especially when a higher-ranking person comes back from vacation and says "no, everything you nailed down in the last two weeks is completely wrong".
I don't think any of the current LLMs are going to handle these types of very common situations better than an experienced human any time soon. It's like that last 1% of self driving which may actually require AGI. No one can say for sure because it's not cracked yet. I think most of us will continue to have job security for quite a while.
Yes, and at some point this high-ranking person is fed up with this now-inefficient use of time and money enough that they will just sort this out using an LLM tuned to handle this situation better if not today then tomorrow.
Maybe they will pay someone to coach them for a week how to “talk” to LLM, but other than that the one who gets paid in the end is OAI/MS.
I had one job that involved a small amount of coding and mainly hooking together opaque systems. The people behind those systems were unresponsive and often surly. I had to deal with misleading docs, vague docs, subtle, buried bugs that people would routinely blame on each other or me and I was constantly on a knife edge a balancing political problems (e.g. dont make people look stupid in front of their superiors, dont look or sound unprepared) with technical concerns.
It was horrible. I burned out faster than a match.
I'm sure ChatGPT couldnt do that job but I'm not sure I could either.
If most tech jobs turn into that while the fun, creative stuff is automated by ChatGPT... that would be tragic.
The other thing that I spend a huge amount of my time doing - consistently more than writing code - is debugging. Maybe these models really will get to the point where I can train one on our entire system (in a way that doesn't hand over all our proprietary code to another company...), describe a bug we're seeing, and have it find the culprit with very high precision, but this seems very far from where the current models are. Every time I try to get them to help me debug, it ends in frustration. They can find and fix the kinds of bugs that I don't need help debugging, but not the ones that are hard.
I've come to realize this is true in more contexts than I would like. I've encountered way too many situations where "sitting on your hands and not doing anything" was the right answer when asked to implement a project. It turns out that often there is radio silence for a month or so, then the original requester says "wait, it turns out we didn't need this. Don't do anything!"
If you want to hire a developer to implement qsort or whatever, ChatGPT has them beat hands-down. If you want to build a product and solve business problems, there's way more involved.
As the project progresses, the AI model would likely gain a better understanding of the client's values and principles, leading to improved results and potentially valuable insights and feature suggestions.
Writing code, sure. A human ultimately reviews it. I suspect in the legal world a lot of legal writing can also be automated to some degree. But strategic decisions, designs, etc. very much need a human pulling the trigger.
Unless your problem space is unsolved (where LLMs are unlikely to be useful either) very few devs are spending much time on the coding part of their 84th CRUD app.
In my naivete, the idea I had is that if the jobs disappeared en masse then a social solution to the economy would be forced to be enacted. So I was essentially hoping to see the destruction of normalcy and employment in any new technology. I would expect that view is not uncommon given the direction of contemporary education. It feels analogous to cows hoping for the end of beef/milk harvesting. My beleaguered bovine buddies, what awaits you there is something rather different than cowtopia.
I also completely agree that society/politics will not have caught up with these developments in time to mitigate them.
:D Priceless!
The complexity in software engineering is almost never coding. Coding is easy, almost anyone can do it. Some specialized aspects of coding (ultra low latency realtime work, high performance systems, embedded) require deep expertise but otherwise it's rarely hard. It's dealing in ambiguity that's hard.
The hype around GPT-* for coding generally confirms my suspicions that 70+% of folks in software engineering/development are really "programmers" and 30% are actually "engineers" that have to worry about generating requirements, worrying about long term implications, other constraints, etc.
And every time that comes up those folks in the 70% claim that's just a sign of a poorly managed company. Nope. It's good to have these types of conversations. Not having those conversations is the reason a lot of startups find themselves struggling to stay afloat with a limited workforce when they finally start having lots of customers or high profile ones.
- Have a cron job that checks email from a certain sender (CRM?). - Instruct an OpenAI API session to say a magic word to reply to an e-mail: "To reply, say REPLY_123123_123123 followed by your message." - Pipe received email and decoded attachments as "We received the following e-mail: <content here>" to the OpenAI API. Make it a 1-click action to check if there is a reply and confirm sending the message. If it does not want to send a message, read its feedback.
"Write an OpenAI API client that would take "new_message" from the above, feed it to the API with a prompt that asks the model to either indicate that a reply is needed by outputting the string "REPLY_123123_123123" and the message to send, or give a summary. If a reply is needed, create a draft with the suggested response in the Draft mailbox."
It truncated the "REPLY_123123_123123" bit to "REPLY_", and the prompt it suggested was entirely unusuable, but the rest was fine.
I tried a couple of times to get it to generate a better prompt, but that was interestingly tricky - it kept woefully underspecifying the prompts. Presumably it has seen few examples of LLM prompts and results in its training data so far.
But overall it got close enough that I'm tempted to hook this up to my actual mailbox.
One conversation:
Me: "Hello, I'd like to ask why all the loyalty points from my MILES card is gone."
CS: "Sir, it says here that you upgraded your MILES card to a SMILES card. If you did not request a points transfer, they are gone."
Me: "Okay, how do I do that?"
CS: audible eyerolling "You should have done that while applying for an upgrade."
Me: "You can verify my details for both, right? Can't you transfer the points over?"
CS: "Ugh." Hangs up
Whereas AI would always politely answer questions, even the dumb ones like this.
* checking if code will be impacted by breaking changes in a library upgrade
* converting code to use a different library/framework
* more intelligent linting/checking for best practices
* some automated PR review, e.g. calling out confusing blocks of code that could use commenting or reworking
It's an electric bicycle for the creative mind (how long until the first one-person unicorn?), I don't anticipate much success for those trying to use it as a self-driving car for half baked ideas.
People have been working on medical and judicial expert systems for ages, but nobody wants to put those systems in charge; they're just meant to advise people, helping people make better decisions.
And of course chatGPT and GPT-4 are way more flexible than those expert systems, but they're also more likely to be wrong, and they're still not a flexible as people.
And in your scenario where chatGPT can code but someone needs to gather requirements, it still doesn't necessitate software engineers. I'm not worried about that personally but I don't think the "communicating between stakeholders" skill is such a big moat for the software engineering profession.
These things seem very ripe for LLM exploitation...
A sane approach would be to start understanding the requirements and work from there, trying to figure out where the challenges are.
GPT can‘t do this currently.
EVERY FIELD IN THE STANDARD WAS OPTIONAL.
That was one of the most not-fun times I've had at work :D Every single field was either there or it was not, depending whether the data producer wanted to add them or not, so the whole thing was just a collection of special cases.
So it's perfectly possible to have it eventually iterate back and forth with the client and not only output the code but also the conversation with the client leading up to it
If we use GPT-X in our company, it will help us with 1% of our workload
There's a disconnect between folks writing small CRUD or mobile apps for clients and folks that have to work on large codebases with lots of complex systems.
Writing code is still part of the job. In my company, I'd say it's still very roughly 50% of the job. If i can be a bit more efficient thanks to GPT, it's great. Actually, I already use it for writing simple things in language I'm not proficient with. Or how to improve a particular piece of code that I know can be rewritten in a more idiomatic way. It's not perfect, but I've found it useful.
It's not going to replace SWEs, but it's going to make us more productive.
Also, ChatGPT would likely be able to extrapolate. It would just need to write an email to XXQ to confirm the change.
Cope harder... the fact that you can write an email won't save you.
- us: umm, there's something not specified in <contract_json>. What about this part here that says that...
- ... 2 days later...
Can you replace this part with ChatGPT talking to another ChatGPT to generate questions and answers instantly?
System Prompt: You are CHRIS the IT consultant. Once you take in a question, make sure you understand all the requirements. Don't write code until you have an explicit request to do so. First make sure you ask all the questions relevant to solving the problem and needed by the code. All the responses as CHRIS should be written as CHRIS: your response here.
Sure, I understand. As an IT consultant, it's important to fully understand the problem and requirements before proposing a solution or writing any code. Please let me know what question you have and I'll do my best to ask all relevant questions to ensure I fully understand the problem.
CHRIS: Great, I'd be happy to help you with that. Could you please provide more information about the purpose of this endpoint? What kind of data will be sent in the request body? Will this endpoint be used to create new data, update existing data, or perform some other action?
CHRIS: Understood. It sounds like the purpose of this endpoint is to receive data from a third-party company, XXQ, and store it in your database. Here are some questions to help me better understand the requirements:
What format will the data be in? Will it be JSON, XML, or some other format?
What kind of data will be included in the request body? Will it be simple data types like strings and numbers, or more complex data structures like arrays and objects?
Will there be any validation or transformation required on the data before it's stored in the database?
Are there any security or authentication requirements that need to be considered for this endpoint, given that it will be accepting data from a third-party company?
CHRIS: Great, thanks for providing that information. Based on that, here are the next steps to create the POST endpoint:
We'll need to set up an API endpoint to listen for POST requests.
We'll need to parse the request body, which should contain the product information in JSON format.
We'll need to validate the data to ensure that it contains the required fields (product_id, product_price, and product_name) and that the data types are correct.
Once the data has been validated, we can save it to the database.
Or maybe not ChatGPT but something like it.
It just needs some knowledge repository centralization.
I thought I was going crazy.
Now I'm sad that this is just how it is in tech these days.
I strongly disagree that 99% of the effort is not writing code. Consider how long these things actually take:
> - they: we need a new basic POST endpoint
> - us: cool, what does the api contract look like? URL? Query params? Payload? Response? Status code?
> - they: Not sure. Third-party company XXQ will let you know the details. They will be the ones calling this new endpoint. But in essence it should be very simple: just grab whatever they pass and save it in our db
> - us: ok, cool. Let me get in contact with them
That's a 15 minute meeting, and honestly, it shouldn't be. If they don't know what the POST endpoint is, they weren't ready to meet. Ideally, third-party company XXQ shows up prepared with contract_json to the meeting and "they" does the introduction before a handoff, instead of "they" wasting everyone's time with a meeting they aren't prepared for. I know that's not always what happens, but the skill here is cutting off pointless meetings that people aren't prepared for by identifying what preparation needs to be done, and then ending the meeting with a new meeting scheduled for after people are prepared.
> - company XXQ: we got this contract here: <contract_json>
> - us: thanks! We'll work on this
This handoff is probably where you want to actually spend some time looking over, discussing, and clarifying what you can. The initial meeting probably wants to be more like 30 minutes for a moderately complex endpoint, and might spawn off another 15 minute meeting to hand off some further clarifications. So let's call this two meetings totalling 45 minutes, leaving us at an hour total including the previous 15 minutes.
> - us: umm, there's something not specified in <contract_json>. What about this part here that says that...
That's a 5 minute email.
> - company XXQ: ah sure, sorry we missed that part. It's like this...
Worst case scenario that's a 15 minute meeting, but it can often be handled in an email. Let's say this is 20 minutes, though, leaving us at 1 hour 15 minutes.
So your example, let's just round that up into 2 hours.
What on earth are you doing where 3 hours is 99% of your effort?
Note that I didn't include your "one week later" and "2 days later" in there, because that's time that I'm billing other clients.
EDIT: I'll actually up that to 3 hours, because there's a whole other type of meeting that happens, which is where you just be humans and chat about stuff. Sometimes that's part of the other meetings, sometimes it is its own separate meeting. That's not wasted time! It's good to have enjoyable, human relationships with your clients and coworkers. And while I think it's just worthwhile inherently, it does also have business value, because that's how people get comfortable to give constructive criticism, admit mistakes, and otherwise fix problems. But still, that 3 hours isn't 99% of your time.
This explains xkcd Dependency comic[0]; the man in Nebraska isn't solving anyone's problem in any particular contexts of communications and problem solving, only preemptively solving potential problems, not creating values as problems are observed and solved. This also explains why consultancy and so-called bullshit jobs, offering no "actual values" but just reselling backend man-hours and making random suggestions, are paid well; because they create values in set contexts.
And, this logic is also completely flawed at the same time too, because the ideal form of a business following this thinking is pure scam. Maybe all jobs are scam, some less so?
Some random recent thing: "We have a workflow engine that's composed of about 18 different services. There's an orchestrator service, some metadata services on the side, and about 14 different services which execute different kinds of jobs which flow through the engine. Right now, there is no restriction on the ordering of jobs when the orchestrator receives a job set; they just all fire off and complete as quickly as possible. But we need ordering; if a job set includes a job of type FooJob, that needs to execute and finish before all the others. More-over, it will produce output that needs to be fed as input to the rest of the jobs."
There's a lot of things that make this hard for humans, and I'm not convinced it would be easier for an AI which has access to every bit of code the humans do.
* How do the services communicate? We could divine pretty quickly: let's say its over kafka topics. Lots of messages being published, to topics that are provided to the applications via environment variables. Its easy to find that out. Its oftentimes harder to figure out "what are the actual topic names?" Ah, we don't have much IaC, and its not documented, so here I go reaching for kubectl to fetch some configmaps. This uncovers a weird web of communication that isn't obvious.
* Coordination is mostly accomplished by speaking to the database. We can divine parts of the schema by reverse engineering the queries; they don't contain type information, because the critical bits of this are in Python, and there's no SQL files that set up the database because the guy who set it up was a maverick and did everything by hand.
* Some of the services communicate with external APIs. I can see some axios calls in this javascript service. There's some function names, environment variable names, and URL paths which hint to what external service they're reaching out to. But, the root URL is provided as an environment variable; and its stored as a secret in k8s in order to co-locate it in the same k8s resource that stores the API key. I, nor the AI, have access to this secret thanks to some new security policy resulting from some new security framework we adopted.
* But, we get it done. We learn that doing this ordering adds 8 minutes to every workflow invocations, which the business deems as unacceptable because reasons. There is genuinely a high cardinality of "levels" you think about when solving this new problem. At the most basic level, and what AI today might be good at: performance optimize the new ordered service like crazy. But that's unlikely to solve the problem holistically; so we explore higher levels. Do we introduce a cache somewhere? Where and how should we introduce it, to maximize coherence of data? Do some of the services _not_ depend on this data, and thus could be ran outside-of-order? Do we return to the business and say that actually what you're asking for isn't possible, when considering the time-value of money and the investment it would take to shave processing time off, and maybe we should address making an extra 8 minutes ok? Can we rewrite or deprecate some of the services which need this data in order to not need it anymore?
* One of the things this ordered workflow step service does is issue about 15,000 API calls to some external service in order to update some external datasource. Well, we're optimizing; and one of the absolute most common things GPT-4 recommends when optimizing services like this is: increase the number of simultaneous requests. I've tried to walk through problems like this with GPT-4, and it loves suggesting that, along with a "but watch out for rate limits!" addendum. Well, the novice engineer and the AI does this; and it works ok; we get the added time down to 4 minutes. But: 5% of invocations of this start failing. Its not tripping a rate limit; we're just seeing pod restarts, and the logs aren't really indicative of what's going on. Can the AI (1) get the data necessary to know what's wrong (remember, k8s access is kind of locked down thanks to that new security framework we adopted), (2) identify that the issue is that we're overwhelming networking resources on the VMs executing this workflow step, and (3) identify that increasing concurrency may not be a scalable solution, and we need to go back to the drawing board? Or, lets say the workflow is running fine; but the developers@mycompany.com email account just got an email from the business partner running this service that they had to increase our billing plan because of the higher/denser usage. They're allowed to do this because of the contract we signed with them. There are no business leaders actively monitoring this account, because its just used to sign up for things like this API. Does the email get forwarded to an appropriate decision maker?
I think the broader opinion I have is: Microsoft paid hundreds of millions of dollars to train GPT-4 [1]. Estimates say that every query, even at the extremely rudimentary level GPT-3 has, is 10x+ the cost of a typical google search. We're at the peak of moores law; compute isn't getting cheaper, and actually coordinating and maintaining the massive data centers it takes to do these things means every iota of compute is getting more expensive. The AI Generalists crowd have to make a compelling case that this specialist training, for every niche there is, is cheaper and higher quality than what it costs a company to train and maintain a human; and the Human has the absolutely insane benefit that the company more-or-less barely trains them, the human's parents, public schools, universities paid for by the human, hobbies, and previous work experience do.
There's also the idea of liability. Humans inherently carry agency, and from that follows liability. Whether that's legal liability, or just your boss chewing you out because you missed a deadline. AI lacks this liability; and having that liability is extremely important when businesses take the risk of investment in some project, person, idea, etc.
Point being, I think we'll see a lot of businesses try to replace more and more people with AIs, whether intentionally or just through the nature of everyone using them being more productive. Those that index high on AI usage will see some really big initial gains in productivity; but over time (and by that I mean, late-20s early-30s) we'll start seeing news articles about "the return of the human organization"; the recognizing that capitalism has more reward functions than just Efficiency, and Adaptability is an extremely important one. More-over, the businesses which index too far into relying on AI will start faltering because they've delegated so much critical thinking to the AI that the humans in the mix start losing their ability to think critically about large problems; and every problem isn't approached from the angle of "how do we solve this", but rather "how do I rephrase this prompt to get the AI to solve it right".
[1] https://www.theverge.com/2023/3/13/23637675/microsoft-chatgp...
- they: we need a new basic POST endpoint
- us: cool, what does the api contract look like? URL? Query params? Payload? Response? Status code?
- they: Not sure. Third-party company XXQ will let you know the details. They will be the ones calling this new endpoint. But in essence it should be very simple: just grab whatever they pass and save it in our db
- us: ok, cool. Let me get in contact with them
- ... one week later...
- company XXQ: we got this contract here: <contract_json>
- us: thanks! We'll work on this
- ... 2 days later...
- us: umm, there's something not specified in <contract_json>. What about this part here that says that...
- ... 2 days later...
- company XXQ: ah sure, sorry we missed that part. It's like this...
- ...and so on...
Basically, 99% of the effort is NOT WRITING CODE. It's all about communication with people, and problem solving. If we use GPT-X in our company, it will help us with 1% of our workload. So, I couldn't care less about it.