Even if llamacpp isnt used for batch inference now, this can allow those to finally run llamacpp for batching and on any hardware since vLLM supports only select hardware. Maybe finally we can stop all this gpu api software fragmentation and cuda moat as llamacpp benchmarks have shown Vulkan to be as or more performant than cuda or sycl.
[1] https://miro.medium.com/v2/resize:fit:1400/format:webp/1*lab...
{kind=link}
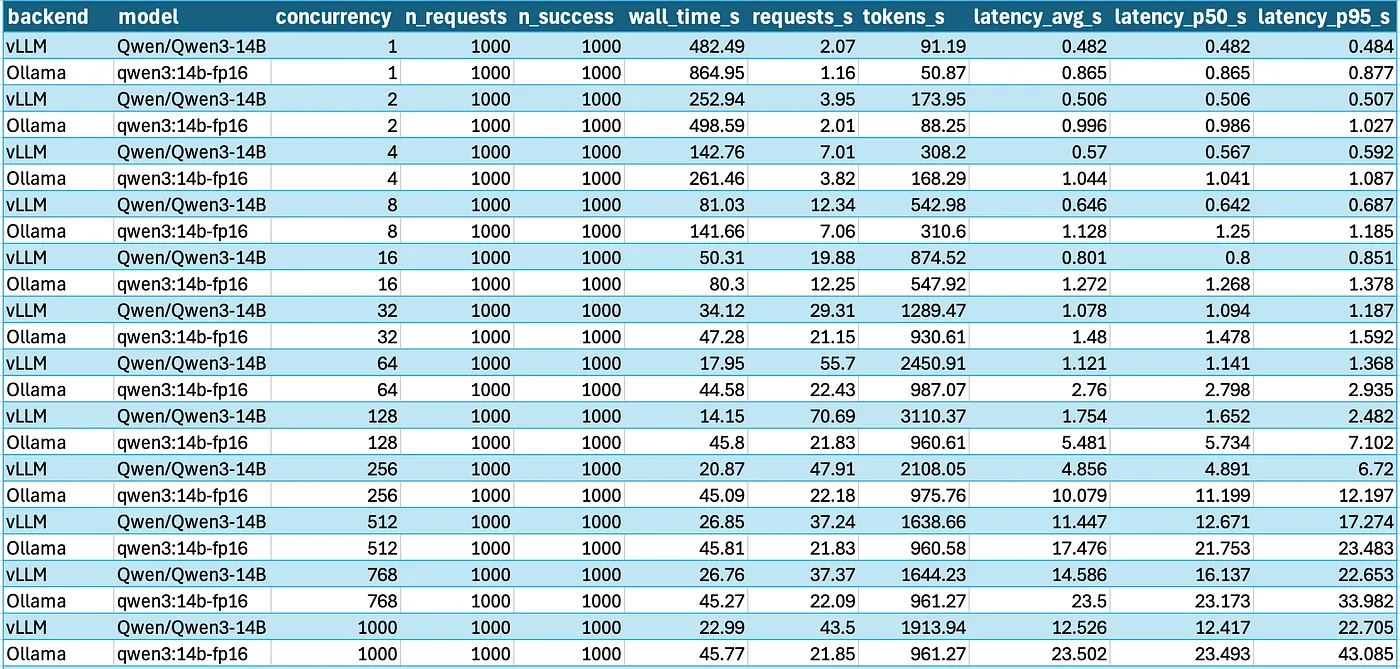
I believe batching is a concept only useful when during the training or fine tuning process.
For local hosting, a more likely scenario where you could use batching is if you had a lot of different data you wanted to process (lots of documents or whatever). You could batch them in sets of x and have it complete in 1/x the time.
A less likely scenario is having enough users that you can make the first user wait a few seconds while you wait to see if a second user submits a request. If you do get a second request, then you can batch them and the second user will get their result back much faster than if they had had to wait for the first user’s request to complete first.
Most people doing local hosting on consumer hardware won’t have the extra VRAM for the KV cache for multiple simultaneous inferences though.